Motivation
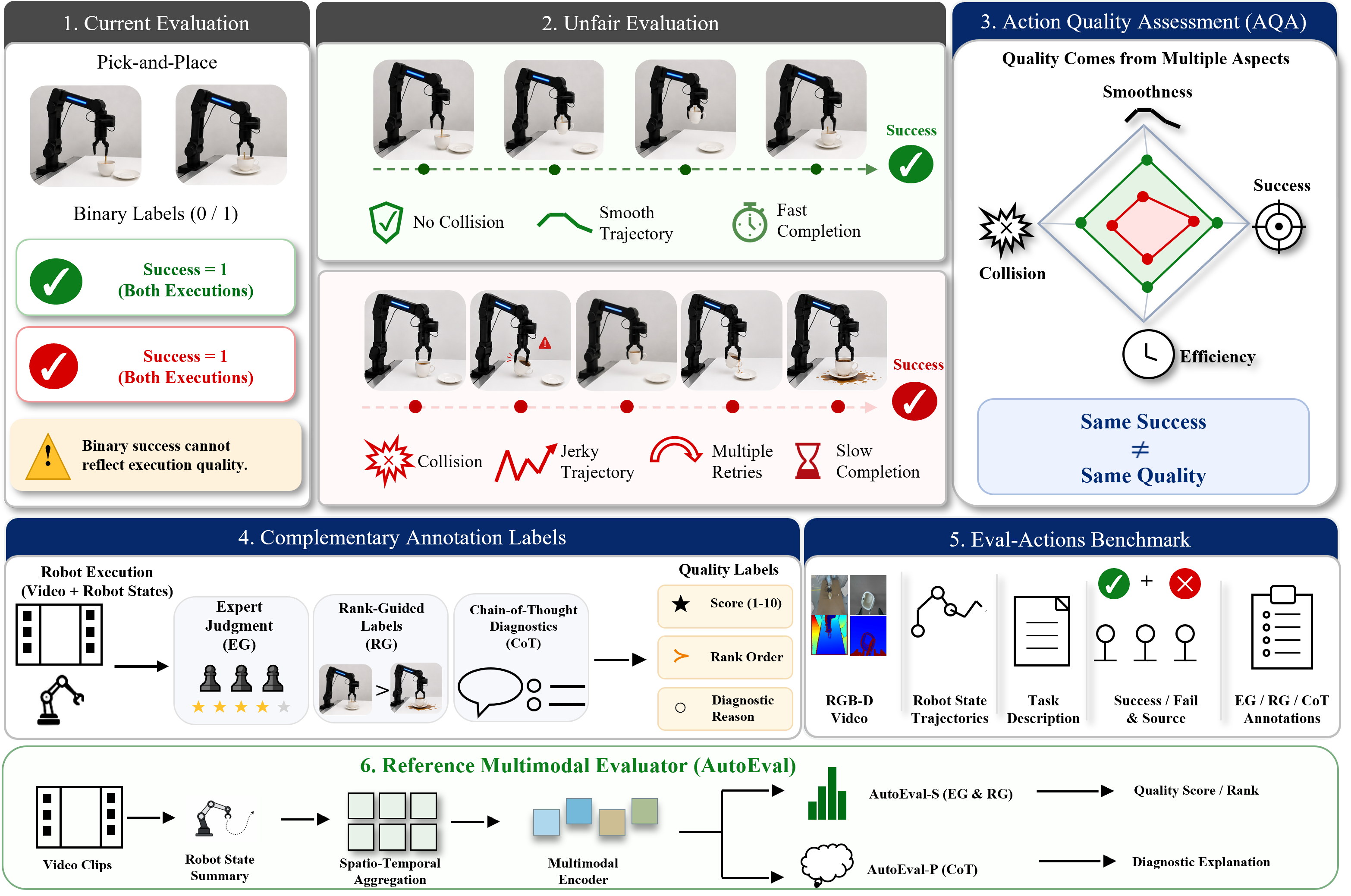
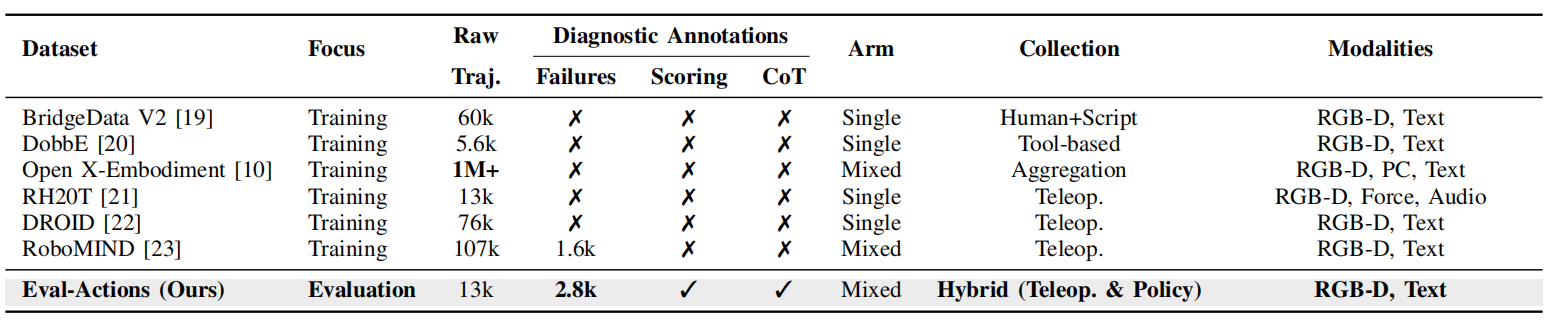
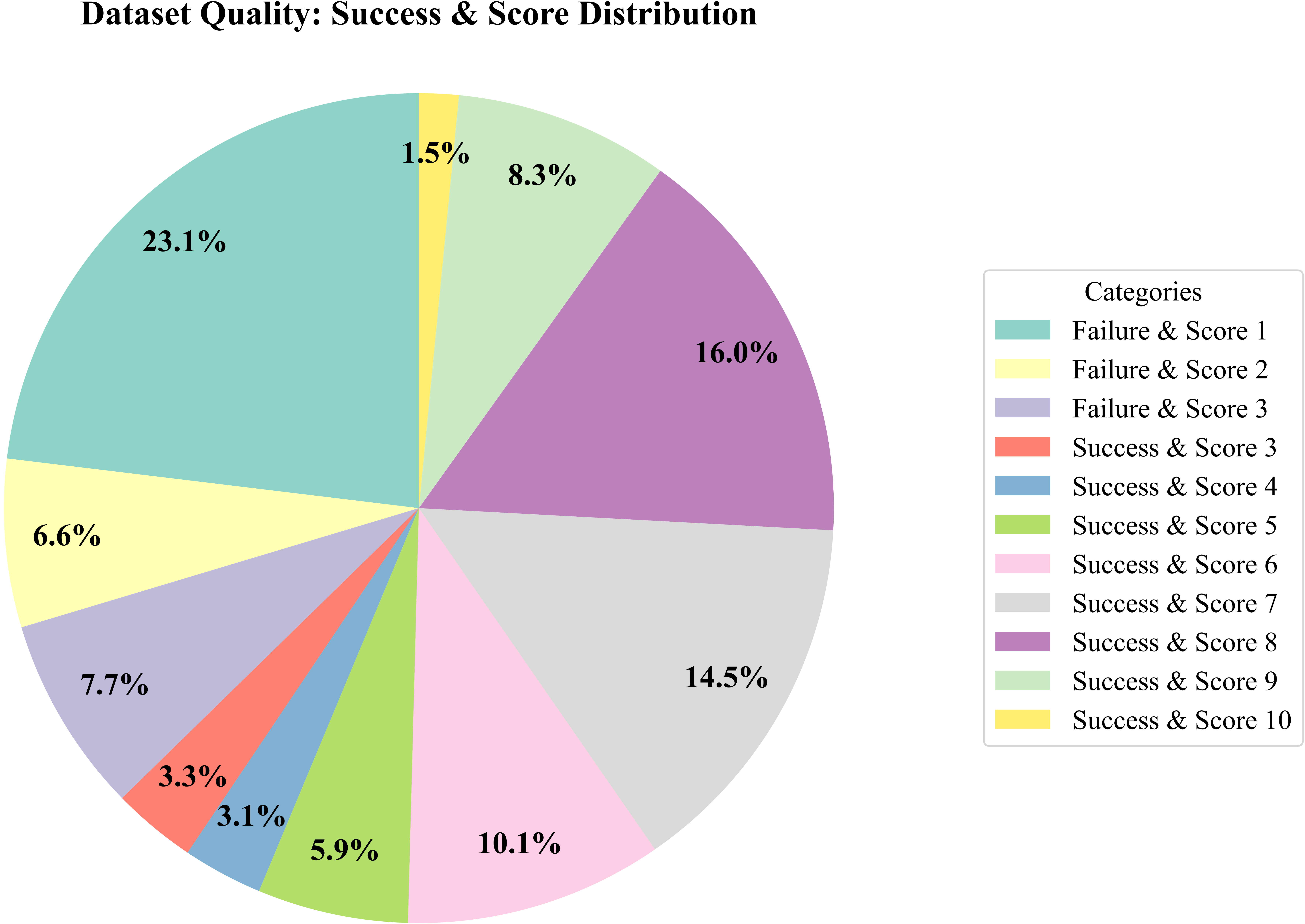
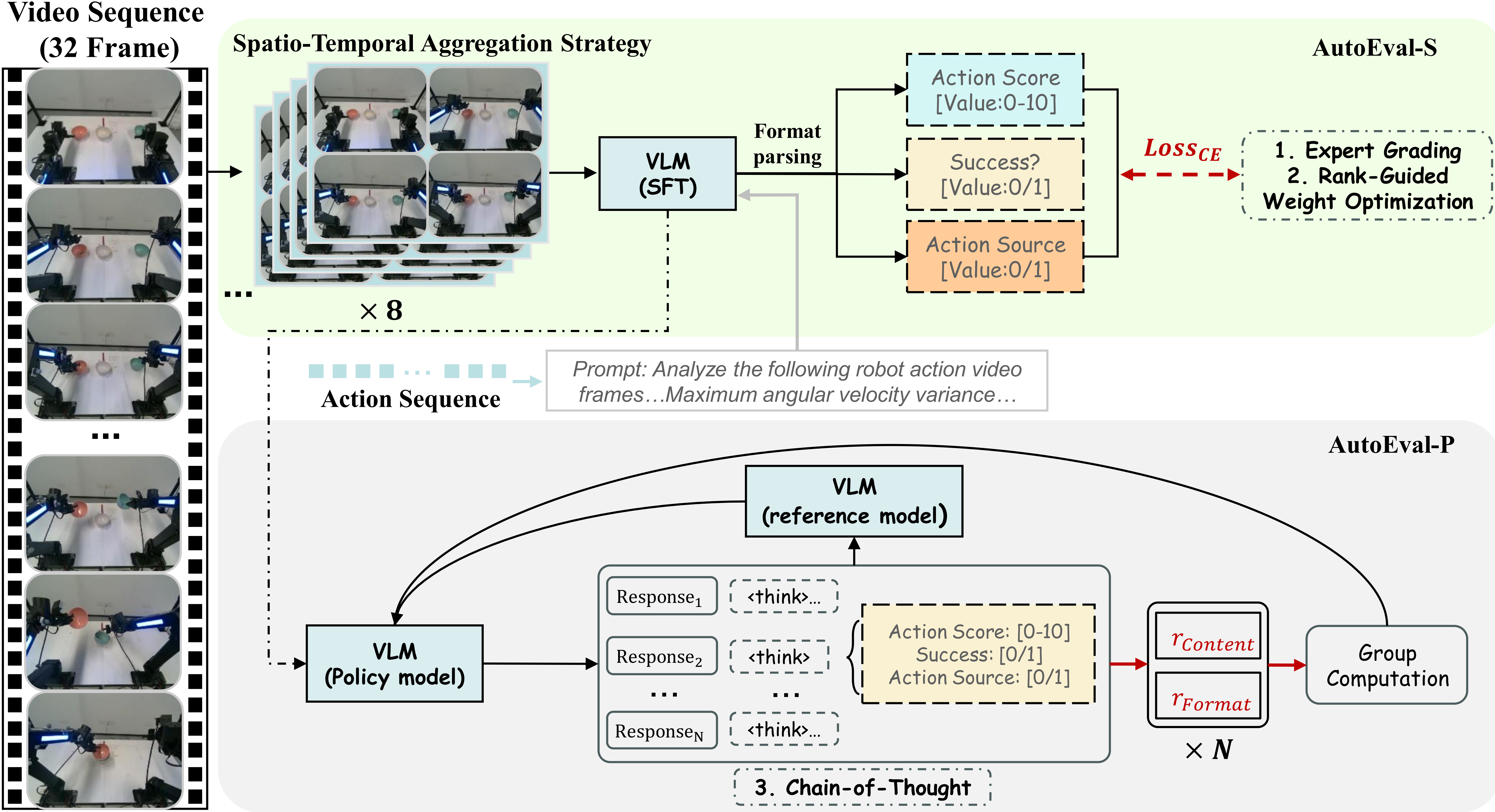
Figure 1. Motivation and overview of the Eval-Actions diagnostic evaluation framework. Conventional manipulation evaluation often reduces each execution to a binary success/failure label, which cannot distinguish process quality among successful executions. Eval-Actions assesses execution quality from task completion, motion smoothness, execution efficiency, and visible collision-related events, provides EG/RG/CoT annotation labels, and introduces AutoEval as a reference multimodal evaluator for quality scores, rankings, and CoT-style diagnostic explanations.